Aktualisiert am: 5. November 2024
25 Minuten Lesezeit
Kontinuierliche Bereitstellung in fünf Umgebungen mithilfe von untergeordneten Pipelines
Erfahre, wie du die kontinuierliche Bereitstellung in verschiedenen Umgebungen – darunter temporäre, sofort einsatzbereite Sandboxes – mit einem minimalistischen GitLab-Workflow verwalten kannst.


Manchmal brauchen DevSecOps-Teams die Möglichkeit, die kontinuierliche Bereitstellung über mehrere Umgebungen übergreifend zu verwalten, ohne dabei ihre Workflows zu verändern. Die DevSecOps-Plattform von GitLab macht dies mit einem minimalistischen Ansatz möglich, unter anderem für temporäre, sofort einsatzbereite Sandboxes. In diesem Artikel erfährst du, wie du die kontinuierliche Bereitstellung der Infrastruktur mit Terraform in verschiedenen Umgebungen ausführen kannst.
Diese Strategie kann einfach auf andere Projekte umgesetzt werden, egal, ob es sich um Infrastructure as Code (IaC), die auf einer anderen Technologie wie Pulumi oder Ansible basiert, um Quellcode in beliebigen Sprachen oder ein Monorepo handelt, bei dem viele Sprachen gemischt verwendet werden.
Die letzte Pipeline, die du am Ende dieses Tutorials hast, stellt Folgendes bereit:
- Eine temporäre Review-Umgebung für jeden Feature-Branch.
- Eine Integrationsumgebung, die einfach zu löschen und vom Haupt-Branch aus bereitzustellen ist.
- Eine QA-Umgebung, die ebenfalls von dem Haupt-Branch bereitgestellt wird, um Qualitätssicherungsschritte durchzuführen.
- Eine Staging-Umgebung, die für jedes Tag bereitgestellt wird. Dies ist die letzte Runde vor der Produktion.
- Eine Produktionsumgebung, die direkt nach der Staging-Umgebung folgt. Diese wird zur Demonstration manuell ausgelöst, kann aber auch kontinuierlich bereitgestellt werden.
Hier findest du die Legende für die Flussdiagramme in diesem Artikel:
- Runde Boxen sind die GitLab-Branches.
- Eckige Boxen sind die Umgebungen.
- Der Text auf den Pfeilen sind die Aktionen, die von einem Feld zum nächsten fließen sollen.
- Eckige Quadrate sind Entscheidungsschritte.
flowchart LR
A(main) -->|new feature| B(feature_X)
B -->|auto deploy| C[review/feature_X]
B -->|merge| D(main)
C -->|destroy| D
D -->|auto deploy| E[integration]
E -->|manual| F[qa]
D -->|tag| G(X.Y.Z)
F -->|validate| G
G -->|auto deploy| H[staging]
H -->|manual| I{plan}
I -->|manual| J[production]
Bei jedem Schritt erfährst du das Warum und das Was, bevor du zum Wie übergehst. Dies wird dir helfen, dieses Tutorial vollständig zu verstehen und zu replizieren.
Warum
-
Kontinuierliche Integration ist fast ein De-facto-Standard. Die meisten Unternehmen haben CI-Pipelines implementiert oder sind bereit, ihre Arbeitsweise zu standardisieren.
-
Kontinuierliche Bereitstellung, wobei Artefakte in ein Repository oder eine Registry am Ende der CI-Pipeline gepusht werden, ist ebenfalls beliebt.
-
Kontinuierliche Bereitstellung, die weiter geht und diese Artefakte automatisch bereitstellt, ist allerdings weniger verbreitet. Wenn, dann wird sie vor allem im Bereich von Anwendungen implementiert. Wenn es um die kontinuierliche Bereitstellung von Infrastruktur geht, scheint das Bild weniger klar zu sein und es dreht sich vieles um das Management mehrerer Umgebungen. Im Gegensatz dazu scheint das Testen, Sichern und Überprüfen des Infrastruktur-Codes schwieriger zu sein. Dies ist eines der Felder, in denen DevOps noch nicht ausgereift ist. Ein anderer Anwendungsbereich ist, die Sicherheit im Vorfeld zu kontrollieren und Sicherheitsteams sowie – was noch wichtiger ist – Sicherheitsbedenken früher in den Lebenszyklus der Bereitstellung zu integrieren und so von DevOps auf DevSecOps upzugraden.
Angesichts dessen wirst du in diesem Tutorial eine einfache und doch effiziente Möglichkeit erarbeiten, DevSecOps für deine Infrastruktur zu implementieren, indem du beispielsweise Ressourcen in fünf Umgebungen bereitstellst und dich schrittweise von der Entwicklung bis zur Produktion vorarbeitest.
Hinweis: Auch wenn ich einen FinOps-Ansatz und eine Reduktion der Umgebungen befürworte, gibt es manchmal gute Gründe, mehr als nur Entwicklung, Staging und Produktion aufrechtzuerhalten. Bitte passe die folgenden Beispiele an deine Bedürfnisse an.
Was
Der Aufstieg der Cloud-Technologie hat die Nutzung von IaC vorangetrieben. Ansible und Terraform gehörten in diesem Bereich zu den Pionieren. OpenTofu, Pulumi, AWS CDK, Google Deploy Manager und viele andere folgten.
IaC gilt als perfekte Lösung, um sich bei der Bereitstellung von Infrastruktur sicher zu fühlen. Du kannst sie testen, bereitstellen und immer wieder abspielen, bis du dein Ziel erreicht hast.
Leider sehen wir oft, dass Unternehmen für jede ihrer Zielumgebungen mehrere Branches oder sogar Repositories unterhalten. Und hier beginnen die Probleme. Sie setzen einen Prozess nicht mehr durch. Sie stellen nicht mehr sicher, dass Änderungen in der Produktions-Codebase in früheren Umgebungen genauestens getestet wurden. Und sie beginnen, Drifts von einer Umgebung in die andere zu erleben.
Mir wurde klar, dass dieses Tutorial notwendig war, als auf einer Konferenz alle Teilnehmenden sagten, dass sie keinen Workflow haben, der durchsetzt, dass Infrastruktur genau getestet wird, bevor sie für die Produktion bereitgestellt wird. Und sie waren sich alle einig, dass sie manchmal den Code direkt in die Produktion patchen. Klar geht das schnell, aber ist es auch sicher? Wie meldet man an frühere Umgebungen zurück? Wie stellt man sicher, dass es keine Nebeneffekte gibt? Wie kontrolliert man, ob man das Unternehmen in Gefahr bringt, wenn neue Sicherheitslücken zu schnell in die Produktion gepusht werden?
Die Frage, warum DevOps-Teams direkt in die Produktion implementieren, ist hier entscheidend. Liegt es daran, dass die Pipeline effizienter oder schneller sein könnte? Gibt es keine Automatisierung? Oder, noch schlimmer, gibt es keine Möglichkeit, außerhalb der Produktion genau zu testen?
Im nächsten Abschnitt erfährst du, wie du Automatisierung für deine Infrastruktur implementieren und sicherstellen kannst, dass dein DevOps-Team effektiv testet, bevor etwas in eine Umgebung gepusht wird, die sich auf andere auswirkt. Du wirst sehen, wie dein Code gesichert und seine Bereitstellung durchgehend kontrolliert wird.
Wie
Wie bereits erwähnt, gibt es heutzutage viele Programmiersprachen für IaC, und wir können ganz einfach nicht alle in einem einzigen Artikel behandeln. Ich werde mich also auf einen grundlegenden Terraform-Code konzentrieren, der auf Version 1.4 läuft. Bitte fixiere dich nicht auf die Programmiersprache für IaC selbst, sondern auf den Prozess, den du für dein eigenes Ökosystem umsetzen kannst.
Der Terraform-Code
Beginnen wir mit einem grundlegenden Terraform-Code.
Wir werden auf AWS bereitstellen, eine virtuelle private Cloud (VPC), die ein virtuelles Netzwerk ist. In dieser VPC werden wir ein öffentliches und ein privates Subnetz bereitstellen. Wie der Name schon sagt, handelt es sich um Subnetze der Haupt-VPC. Abschließend fügen wir eine EC2-Instanz (Elastic Cloud Compute; eine virtuelle Maschine) zum öffentlichen Subnetz hinzu.
Dies zeigt, wie vier Ressourcen bereitgestellt werden können, ohne zu komplex zu werden. Die Idee ist, sich auf die Pipeline zu konzentrieren, nicht auf den Code.
Hier ist das Ziel, das wir für dein Repository erreichen möchten.
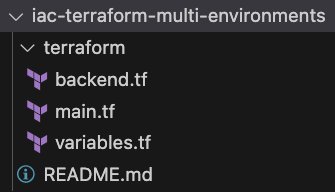
Gehen wir Schritt für Schritt vor.
Zuerst deklarieren wir alle Ressourcen in der Datei terraform/main.tf:
provider "aws" {
region = var.aws_default_region
}
resource "aws_vpc" "main" {
cidr_block = var.aws_vpc_cidr
tags = {
Name = var.aws_resources_name
}
}
resource "aws_subnet" "public_subnet" {
vpc_id = aws_vpc.main.id
cidr_block = var.aws_public_subnet_cidr
tags = {
Name = "Public Subnet"
}
}
resource "aws_subnet" "private_subnet" {
vpc_id = aws_vpc.main.id
cidr_block = var.aws_private_subnet_cidr
tags = {
Name = "Private Subnet"
}
}
resource "aws_instance" "sandbox" {
ami = var.aws_ami_id
instance_type = var.aws_instance_type
subnet_id = aws_subnet.public_subnet.id
tags = {
Name = var.aws_resources_name
}
}
Wie du sehen kannst, sind für diesen Code einige Variablen erforderlich, die wir also in der Datei terraform/variables.tf deklarieren:
variable "aws_ami_id" {
description = "The AMI ID of the image being deployed."
type = string
}
variable "aws_instance_type" {
description = "The instance type of the VM being deployed."
type = string
default = "t2.micro"
}
variable "aws_vpc_cidr" {
description = "The CIDR of the VPC."
type = string
default = "10.0.0.0/16"
}
variable "aws_public_subnet_cidr" {
description = "The CIDR of the public subnet."
type = string
default = "10.0.1.0/24"
}
variable "aws_private_subnet_cidr" {
description = "The CIDR of the private subnet."
type = string
default = "10.0.2.0/24"
}
variable "aws_default_region" {
description = "Default region where resources are deployed."
type = string
default = "eu-west-3"
}
variable "aws_resources_name" {
description = "Default name for the resources."
type = string
default = "demo"
}
Auf der IaC-Seite sind wir damit auch schon fast fertig. Was fehlt, ist eine Möglichkeit, die Terraform-Zustände zu teilen. Für diejenigen, die es nicht wissen: Terraform funktioniert schematisch wie folgt:
planüberprüft die Unterschiede zwischen dem aktuellen Status der Infrastruktur und dem, was im Code definiert ist. Dann gibt es die Unterschiede aus.applywendet die Unterschiede implanan und aktualisiert den Status.
In der ersten Runde ist der Status leer, dann wird er mit den Details (ID usw.) der von Terraform angewendeten Ressourcen gefüllt.
Das Problem ist: Wo wird dieser Zustand gespeichert? Wie können wir ihn teilen, damit mehrere Entwickler(innen) am Code zusammenarbeiten können?
Die Lösung ist ziemlich einfach: Nutze GitLab, um den Status über ein Terraform-HTTP-Backend zu speichern und freizugeben.
Der erste Schritt bei der Verwendung dieses Backends besteht darin, die einfachste Datei, nämlich terraform/backend.tf zu erstellen. Der zweite Schritt erfolgt in der Pipeline.
terraform {
backend "http" {
}
}
Et voilà! Wir haben einen minimalen Terraform-Code, um diese vier Ressourcen bereitzustellen. Wir werden die Variablenwerte zur Laufzeit bereitstellen, also machen wir das später.
Der Workflow
Der Workflow, den wir jetzt implementieren werden, sieht folgendermaßen aus:
flowchart LR
A(main) -->|new feature| B(feature_X)
B -->|auto deploy| C[review/feature_X]
B -->|merge| D(main)
C -->|destroy| D
D -->|auto deploy| E[integration]
E -->|manual| F[qa]
D -->|tag| G(X.Y.Z)
F -->|validate| G
G -->|auto deploy| H[staging]
H -->|manual| I{plan}
I -->|manual| J[production]
- Erstelle einen Feature-Branch. Dadurch werden alle Scanner kontinuierlich auf dem Code ausgeführt, um sicherzustellen, dass er immer konform und gesichert bleibt. Dieser Code wird kontinuierlich in der temporären Umgebung
review/feature_branchmit dem Namen des aktuellen Branches bereitgestellt. Dies ist eine sichere Umgebung, in der die Entwickler(innen) und IT-Betriebsteams ihren Code ohne Auswirkungen auf andere testen können. Hier setzen wir auch den Prozess durch, z. B. indem Code Reviews durchgesetzt und Scanner ausgeführt werden, damit die Qualität und Sicherheit des Codes akzeptabel sind und deine Assets nicht gefährdet werden. Die von diesem Branch bereitgestellte Infrastruktur wird automatisch zerstört, wenn der Branch geschlossen wird. So behältst du dein Budget unter Kontrolle.
flowchart LR
A(main) -->|new feature| B(feature_X)
B -->|auto deploy| C[review/feature_X]
B -->|merge| D(main)
C -->|destroy| D
- Nach der Genehmigung wird der Feature-Branch mit dem Main-Branch zusammengeführt. Dies ist ein geschützter Branch, in den niemand pushen kann. Dies ist obligatorisch, um sicherzustellen, dass jede Änderungsanfrage an die Produktion gründlich getestet wird. Dieser Branch wird auch kontinuierlich bereitgestellt. Das Ziel hier ist die Umgebung
integration. Damit diese Umgebung etwas stabiler bleibt, wird das Löschen nicht automatisiert, sondern kann manuell ausgelöst werden.
flowchart LR
D(main) -->|auto deploy| E[integration]
- Von dort aus ist eine manuelle Genehmigung erforderlich, um die nächste Bereitstellung auszulösen. Dadurch wird der Haupt-Branch in der Umgebung
qabereitgestellt. Hier habe ich eine Regel festgelegt, um das Löschen aus der Pipeline zu verhindern. Diese Umgebung sollte ziemlich stabil sein (schließlich ist es bereits die dritte Umgebung), und ich möchte das versehentliche Löschen verhindern. Du kannst die Regeln gerne an deine Prozesse anpassen.
flowchart LR
D(main)-->|auto deploy| E[integration]
E -->|manual| F[qa]
- Um fortzufahren, müssen wir den Code taggen. Wir setzen hier auf geschützte Tags, um sicherzustellen, dass nur eine bestimmte Gruppe von Benutzer(inne)n in diese letzten beiden Umgebungen bereitstellen darf. Dadurch wird sofort eine Bereitstellung in der Umgebung
stagingausgelöst.
flowchart LR
D(main) -->|tag| G(X.Y.Z)
F[qa] -->|validate| G
G -->|auto deploy| H[staging]
- Schließlich landen wir bei
production. Wenn es um Infrastruktur geht, ist es oft schwierig, sie schrittweise bereitzustellen (10 %, 25 % usw.), sodass wir gleich die gesamte Infrastruktur bereitstellen werden. Dennoch steuern wir diese Bereitstellung, indem dieser letzte Schritt manuell ausgelöst wird. Und um maximale Kontrolle über diese hochkritische Umgebung zu erzwingen, werden wir sie als geschützte Umgebung kontrollieren.
flowchart LR
H[staging] -->|manual| I{plan}
I -->|manual| J[production]
Die Pipeline
Um den oben genannten Workflow zu implementieren, implementieren wir jetzt eine Pipeline mit zwei Downstream-Pipelines.
Die Haupt-Pipeline
Beginnen wir mit der Haupt-Pipeline. Dies ist diejenige, die automatisch bei jedem Push zu einem Feature-Branch, jedem Zusammenführen zum Standard-Branch** oder jedem Tag ausgelöst wird. Die Pipeline, die eine echte kontinuierliche Bereitstellung in den folgenden Umgebungen durchführt: dev, integration und staging. Und das wird in der Datei .gitlab-ci.yml im Stamm deines Projekts deklariert.

Stages:
- test
- environments
.environment:
stage: environments
variables:
TF_ROOT: terraform
TF_CLI_ARGS_plan: "-var-file=../vars/$variables_file.tfvars"
trigger:
include: .gitlab-ci/.first-layer.gitlab-ci.yml
strategy: depend # Wait for the triggered pipeline to successfully complete
forward:
yaml_variables: true # Forward variables defined in the trigger job
pipeline_variables: true # Forward manual pipeline variables and scheduled pipeline variables
review:
extends: .environment
variables:
environment: review/$CI_COMMIT_REF_SLUG
TF_STATE_NAME: $CI_COMMIT_REF_SLUG
variables_file: review
TF_VAR_aws_resources_name: $CI_COMMIT_REF_SLUG # Used in the tag Name of the resources deployed, to easily differenciate them
rules:
- if: $CI_COMMIT_BRANCH && $CI_COMMIT_BRANCH != $CI_DEFAULT_BRANCH
integration:
extends: .environment
variables:
environment: integration
TF_STATE_NAME: $environment
variables_file: $environment
rules:
- if: $CI_COMMIT_BRANCH == $CI_DEFAULT_BRANCH
staging:
extends: .environment
variables:
environment: staging
TF_STATE_NAME: $environment
variables_file: $environment
rules:
- if: $CI_COMMIT_TAG
#### TWEAK
# This tweak is needed to display vulnerability results in the merge widgets.
# As soon as this issue https://gitlab.com/gitlab-org/gitlab/-/issues/439700 is resolved, the `include` instruction below can be removed.
# Until then, the SAST IaC scanners will run in the downstream pipelines, but their results will not be available directly in the merge request widget, making it harder to track them.
# Note: This workaround is perfectly safe and will not slow down your pipeline.
include:
- template: Security/SAST-IaC.gitlab-ci.yml
#### END TWEAK
Diese Pipeline läuft nur in zwei Phasen: test und environments. Erstere wird benötigt, damit der TWEAK Scanner ausführen kann. Zweitere löst eine untergeordnete Pipeline mit einem anderen Satz von Variablen für jeden oben definierten Fall aus (Push zum Branch, Zusammenführen zum Standard-Branch oder Tag).
Wir fügen hier eine Abhängigkeit mit dem Schlüsselwort strategy:depend zu unserer untergeordneten Pipeline hinzu, sodass die Pipeline-Ansicht in GitLab erst aktualisiert wird, wenn die Bereitstellung abgeschlossen ist.
Wie du hier sehen kannst, definieren wir einen Basisjob, hidden, und erweitern ihn um bestimmte Variablen und Regeln, um nur eine Bereitstellung für jede Zielumgebung auszulösen.
Neben den vordefinierten Variablen verwenden wir zwei neue Einträge, die wir definieren müssen:
- Die für jede Umgebung spezifischen Variablen:
../vars/$variables_file.tfvars - Die untergeordnete Pipeline, definiert in
.gitlab-ci/.first-layer.gitlab-ci.yml
Beginnen wir mit dem kleinsten Teil, den Variablendefinitionen.
Die Variablendefinitionen
Wir werden hier zwei Lösungen mischen, um Terraform Variablen zur Verfügung zu stellen:
- Die erste nutzt .tfvars-Dateien für alle nicht sensiblen Eingaben, die in GitLab gespeichert werden sollten.
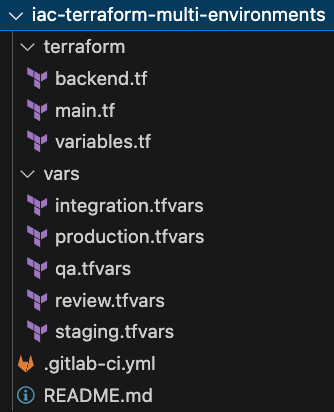
- Die zweite verwendet Umgebungsvariablen mit dem Präfix
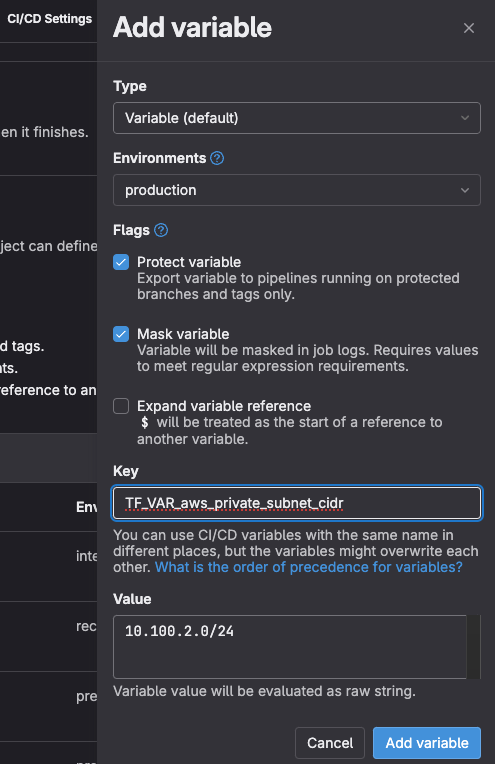
TF_VAR. Diese zweite Möglichkeit, Variablen zu injizieren, die mit der GitLab-Fähigkeit verbunden sind, Variablen zu maskieren, sie zu schützen und sie in Umgebungen zu übertragen, ist eine leistungsstarke Lösung, um Datenlecks sensibler Informationen zu verhindern. (Wenn du das private CIDR deiner Produktion als sehr sensibel betrachtest, könntest du es so schützen, indem du sicherstellst, dass es nur für die Umgebungproductionverfügbar ist, für Pipelines, die gegen geschützte Branches und Tags ausgeführt werden, und dass sein Wert in den Protokollen des Jobs maskiert ist.)
Darüber hinaus sollte jede Variablendatei über eine Datei CODEOWNERS gesteuert werden, um festzulegen, wer sie ändern darf.
[Production owners]
vars/production.tfvars @operations-group
[Staging owners]
vars/staging.tfvars @odupre @operations-group
[CodeOwners owners]
CODEOWNERS @odupre
Dieser Artikel ist kein Terraform-Training, daher halten wir das kurz und zeigen hier einfach die Datei vars/review.tfvars. Die nachfolgenden Umgebungsdateien sind sich natürlich sehr ähnlich. Lege hier einfach die nicht-sensiblen Variablen und ihre Werte fest.
aws_vpc_cidr = "10.1.0.0/16"
aws_public_subnet_cidr = "10.1.1.0/24"
aws_private_subnet_cidr = "10.1.2.0/24"
Die untergeordnete Pipeline
Hier wird die eigentliche Arbeit erledigt. Sie ist also etwas komplexer als die erste Pipeline. Es gibt aber auch hier keine Schwierigkeit, die wir nicht gemeinsam überwinden können!
Wie wir bei der Definition der Haupt-Pipeline gesehen haben, wird diese Downstream-Pipeline in der Datei .gitlab-ci/.first-layer.gitlab-ci.yml deklariert.
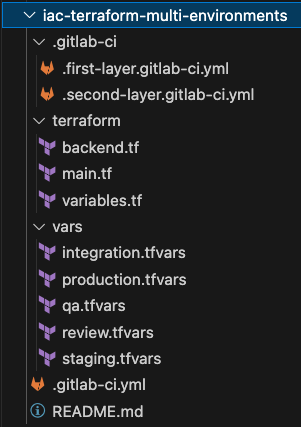
Zerlegen wir sie in kleine Stücke. Am Ende sehen wir dann das große Ganze.
Terraform-Befehle ausführen und den Code sichern
Zuerst wollen wir eine Pipeline für Terraform ausführen. GitLab ist Open Source. Unsere Terraform-Vorlage ist also auch Open Source. Du kannst sie einfach einbeziehen. Dies erreichst du mit folgendem Code-Schnipsel:
include:
- template: Terraform.gitlab-ci.yml
Diese Vorlage führt für dich die Terraform-Prüfungen für die Formatierung durch und validiert deinen Code, bevor er geplant und angewendet wird. Es ermöglicht dir auch, das zu zerstören, was du bereitgestellt hast.
Da GitLab eine vereinheitlichte DevSecOps-Plattform ist, fügen wir dieser Vorlage automatisch zwei Sicherheitsscanner hinzu, um potenzielle Bedrohungen in deinem Code zu finden und dich zu warnen, bevor du ihn in den nächsten Umgebungen bereitstellst.
Jetzt, da wir unseren Code überprüft, gesichert, erstellt und bereitgestellt haben, folgen ein paar Tricks.
Zwischenspeicher zwischen Jobs teilen
Wir werden Job-Ergebnisse zwischenspeichern, um sie in folgenden Pipeline-Jobs wiederzuverwenden. Dies ist einfach, denn du musst nur den folgenden Code hinzufügen:
default:
cache: # Use a shared cache or tagged runners to ensure terraform can run on apply and destroy
- key: cache-$CI_COMMIT_REF_SLUG
fallback_keys:
- cache-$CI_DEFAULT_BRANCH
paths:
- .
Hier definieren wir einen anderen Zwischenspeicher für jeden Commit und greifen bei Bedarf auf den Namen des Haupt-Branchs zurück.
Wenn wir uns die Vorlagen, die wir verwenden, genau ansehen, stellen wir fest, dass sie einige Regeln haben, die zu kontrollieren sind, wenn Jobs ausgeführt werden. Wir wollen alle Kontrollen (sowohl QA als auch Sicherheit) in allen Branchen ausführen. Wir werden diese Einstellungen also überschreiben.
Kontrollen in allen Branches ausführen
GitLab-Vorlagen sind eine leistungsstarke Funktion, bei der man auch nur einen Teil der Vorlage überschreiben kann. Hier wollen wir die Regeln einiger Jobs überschreiben, um immer Qualitäts- und Sicherheitskontrollen durchzuführen. Alles andere, was für diese Jobs definiert ist, bleibt wie in der Vorlage definiert.
fmt:
rules:
- when: always
validate:
rules:
- when: always
kics-iac-sast:
rules:
- when: always
iac-sast:
rules:
- when: always
Da wir nun die Qualitäts- und Sicherheitskontrollen durchgesetzt haben, wollen wir unterscheiden, wie sich die Hauptumgebungen (Integration und Staging) im Workflow und Review-Umgebungen verhalten. Beginnen wir mit der Definition des Verhaltens der Hauptumgebung. Wir werden dann diese Konfiguration für die Review-Umgebungen optimieren.
CD für Integration und Staging
Wie zuvor definiert, möchten wir den Haupt-Branch und die Tags in diesen beiden Umgebungen bereitstellen. Wir fügen Regeln hinzu, um das sowohl bei den Jobs build als auch deploy zu kontrollieren. Dann wollen wir destroy nur für integration aktivieren, da wir definiert haben, dass staging zu kritisch ist, um mit einem einzigen Klick gelöscht zu werden. Das ist fehleranfällig, was wir nicht wollen.
Schließlich verknüpfen wir den Job deploy mit dem Job destroy, damit wir die Umgebung direkt von der GitLab-GUI aus mit stop stoppen können.
Die GIT_STRATEGY soll verhindern, dass der Code beim Zerstören aus dem Quell-Branch im Runner abgerufen wird. Dies würde fehlschlagen, wenn der Branch manuell gelöscht wurde. Daher verlassen wir uns auf den Zwischenspeicher, um alles zu erhalten, was wir zum Ausführen der Terraform-Anweisungen benötigen.
build: # terraform plan
environment:
name: $TF_STATE_NAME
action: prepare
rules:
- if: $CI_COMMIT_BRANCH == $CI_DEFAULT_BRANCH
- if: $CI_COMMIT_TAG
deploy: # terraform apply --> automatically deploy on corresponding env (integration or staging) when merging to default branch or tagging. Second layer environments (qa and production) will be controlled manually
environment:
environment:
name: $TF_STATE_NAME
action: start
on_stop: destroy
rules:
- if: $CI_COMMIT_BRANCH == $CI_DEFAULT_BRANCH
- if: $CI_COMMIT_TAG
destroy:
extends: .terraform:destroy
variables:
GIT_STRATEGY: none
dependencies:
- build
environment:
name: $TF_STATE_NAME
action: stop
rules:
- if: $CI_COMMIT_TAG # Do not destroy production
when: never
- if: $CI_COMMIT_BRANCH == $CI_DEFAULT_BRANCH && $TF_DESTROY == "true" # Manually destroy integration env.
when: manual
Wie gesagt müssen diese Matches in integration und staging bereitstellen. Uns fehlt jedoch immer noch eine temporäre Umgebung, in der die Entwickler(innen) ihren Code ohne Auswirkungen auf andere erleben und validieren können. Hier findet die Bereitstellung in der Umgebung review statt.
CD für Review-Umgebungen
Die Bereitstellung in der Review-Umgebung unterscheidet sich nicht allzu sehr von der Bereitstellung in integration und staging. Wir werden also erneut die Möglichkeit von GitLab nutzen, hier nur Teile der Jobdefinition zu überschreiben.
Zuerst legen wir Regeln fest, um diese Jobs nur in Feature-Branches auszuführen.
Dann verknüpfen wir den Job deploy_review mit destroy_review. Dies ermöglicht es uns, die Umgebung manuell von der GitLab-Bedienoberfläche aus zu stoppen und – was noch wichtiger ist – es wird automatisch die Zerstörung der Umgebung ausgelöst, wenn der Feature-Branch geschlossen wird. Dies ist eine gute FinOps-Praxis, um dir zu helfen, deine Betriebsausgaben zu kontrollieren.
Da Terraform eine Plandatei benötigt, um eine Infrastruktur zu zerstören (genau wie es eine solche Datei benötigt, um eine Infrastruktur aufzubauen), fügen wir eine Abhängigkeit von destroy_review zu build_review hinzu, um Artefakte abzurufen.
Schließlich sehen wir hier, dass der Name der Umgebung auf $environment festgelegt ist. Es wurde in der Haupt-Pipeline auf review/$CI_COMMIT_REF_SLUG gesetzt und mit der Anweisung trigger:forward:yaml_variables:true an diese untergeordnete Pipeline weitergeleitet.
build_review:
extends: build
rules:
- if: $CI_COMMIT_TAG
when: never
- if: $CI_COMMIT_BRANCH != $CI_DEFAULT_BRANCH
when: on_success
deploy_review:
extends: deploy
dependencies:
- build_review
environment:
name: $environment
action: start
on_stop: destroy_review
# url: https://$CI_ENVIRONMENT_SLUG.example.com
rules:
- if: $CI_COMMIT_TAG
when: never
- if: $CI_COMMIT_BRANCH != $CI_DEFAULT_BRANCH
when: on_success
destroy_review:
extends: destroy
dependencies:
- build_review
environment:
name: $environment
action: stop
rules:
- if: $CI_COMMIT_TAG # Do not destroy production
when: never
- if: $CI_COMMIT_BRANCH == $CI_DEFAULT_BRANCH # Do not destroy staging
when: never
- when: manual
Zusammenfassend können wir also sagen, dass wir jetzt eine Pipeline haben, die Folgendes kann:
- Temporäre Review-Umgebungen bereitstellen, die automatisch gelöscht werden, wenn der Feature-Branch geschlossen wird
- Den Standard-Branch kontinuierlich auf
integrationbereitstellen - Die Tags kontinuierlich auf
stagingbereitstellen
Fügen wir nun eine zusätzliche Ebene hinzu, auf der wir diesmal mit einem manuellen Auslöser in den Umgebungen qa und production bereitstellen werden.
Kontinuierliche Bereitstellung in QA und Produktion
Da nicht jedes Unternehmen kontinuierlich in der Produktion bereitstellen möchte, fügen wir den nächsten beiden Bereitstellungen eine manuelle Validierung hinzu. Aus einer reinen CD-Perspektive würden wir diesen Auslöser nicht hinzufügen, aber betrachte dies als Gelegenheit, zu lernen, wie man Jobs von anderen Auslösern aus ausführt.
Bisher haben wir eine untergeordnete Pipeline aus der Haupt-Pipeline gestartet, um alle Bereitstellungen auszuführen.
Da wir andere Bereitstellungen aus dem Standard-Branch und den Tags ausführen möchten, fügen wir eine weitere Ebene für diese zusätzlichen Schritte hinzu. Hier gibt es nichts Neues. Wir wiederholen einfach genau das, was wir nur für die Haupt-Pipeline gemacht haben. Auf diese Weise kannst du so viele Ebenen bearbeiten, wie du brauchst. Ich habe schon einmal bis zu neun Umgebungen gesehen.
Wir wollen hier nicht über die Vorteile diskutieren, die es mit sich bringt, weniger Umgebungen zu haben. Der hier verwendete Prozess macht es jedenfalls sehr einfach, die gleiche Pipeline von der Anfangsphase bis zur endgültigen Lieferung zu implementieren, während deine Pipeline-Definition einfach und in kleine, einfach zu wartende Teile aufgeteilt bleibt.
Um hier Variablenkonflikte zu vermeiden, verwenden wir nur neue Variablennamen, um den Terraform-Status und die Eingabedatei zu identifizieren.
.2nd_layer:
stage: 2nd_layer
variables:
TF_ROOT: terraform
trigger:
include: .gitlab-ci/.second-layer.gitlab-ci.yml
# strategy: depend # Do NOT wait for the downstream pipeline to finish to mark upstream pipeline as successful. Andernfalls schlagen alle Pipelines fehl, wenn eine Pipeline-Zeitüberschreitung vor der Bereitstellung auf die 2. Ebene erreicht wurde.
forward:
yaml_variables: true # Forward variables defined in the trigger job
pipeline_variables: true # Forward manual pipeline variables and scheduled pipeline variables
qa:
extends: .2nd_layer
variables:
TF_STATE_NAME_2: qa
environment: $TF_STATE_NAME_2
TF_CLI_ARGS_plan_2: "-var-file=../vars/$TF_STATE_NAME_2.tfvars"
rules:
- if: $CI_COMMIT_BRANCH == $CI_DEFAULT_BRANCH
production:
extends: .2nd_layer
variables:
TF_STATE_NAME_2: production
environment: $TF_STATE_NAME_2
TF_CLI_ARGS_plan_2: "-var-file=../vars/$TF_STATE_NAME_2.tfvars"
rules:
- if: $CI_COMMIT_TAG
Ein wichtiger Trick ist hier die Strategie, die für die neue Downstream-Pipeline verwendet wird. Wir belassen trigger:strategy auf ihrem Standardwert. Andernfalls würde die Haupt-Pipeline warten, bis deine Pipeline der zweiten Ebene abgeschlossen ist. Bei einem manuellen Auslöser kann dies sehr lange dauern und das Lesen und Verstehen deines Pipeline-Dashboards erschweren.
Du hast dich wahrscheinlich schon gefragt, was der Inhalt der Datei .gitlab-ci/.second-layer.gitlab-ci.yml ist, die wir hier anführen. Wir gehen im nächsten Abschnitt darauf ein.
Vollständige Pipeline-Definition auf der ersten Ebene
Wenn du eine vollständige Ansicht dieser ersten Ebene möchtest (gespeichert in .gitlab-ci/.first-layer.gitlab-ci.yml), erweitere einfach den Abschnitt unten.
variables:
TF_VAR_aws_ami_id: $AWS_AMI_ID
TF_VAR_aws_instance_type: $AWS_INSTANCE_TYPE
TF_VAR_aws_default_region: $AWS_DEFAULT_REGION
include:
- template: Terraform.gitlab-ci.yml
default:
cache: # Use a shared cache or tagged runners to ensure terraform can run on apply and destroy
- key: cache-$CI_COMMIT_REF_SLUG
fallback_keys:
- cache-$CI_DEFAULT_BRANCH
paths:
- .
stages:
- validate
- test
- build
- deploy
- cleanup
- 2nd_layer # Use to deploy a 2nd environment on both the main branch and on the tags
fmt:
rules:
- when: always
validate:
rules:
- when: always
kics-iac-sast:
rules:
- if: $SAST_DISABLED == 'true' || $SAST_DISABLED == '1'
when: never
- if: $SAST_EXCLUDED_ANALYZERS =~ /kics/
when: never
- when: on_success
iac-sast:
rules:
- if: $SAST_DISABLED == 'true' || $SAST_DISABLED == '1'
when: never
- if: $SAST_EXCLUDED_ANALYZERS =~ /kics/
when: never
- when: on_success
###########################################################################################################
## Integration env. and Staging. env
## * Auto-deploy to Integration on merge to main.
## * Auto-deploy to Staging on tag.
## * Integration can be manually destroyed if TF_DESTROY is set to true.
## * Destroy of next env. is not automated to prevent errors.
###########################################################################################################
build: # terraform plan
environment:
name: $TF_STATE_NAME
action: prepare
rules:
- if: $CI_COMMIT_BRANCH == $CI_DEFAULT_BRANCH
- if: $CI_COMMIT_TAG
deploy: # terraform apply --> automatically deploy on corresponding env (integration or staging) when merging to default branch or tagging. Second layer environments (qa and production) will be controlled manually
environment:
name: $TF_STATE_NAME
action: start
on_stop: destroy
rules:
- if: $CI_COMMIT_BRANCH == $CI_DEFAULT_BRANCH
- if: $CI_COMMIT_TAG
destroy:
extends: .terraform:destroy
variables:
GIT_STRATEGY: none
dependencies:
- build
environment:
name: $TF_STATE_NAME
action: stop
rules:
- if: $CI_COMMIT_TAG # Do not destroy production
when: never
- if: $CI_COMMIT_BRANCH == $CI_DEFAULT_BRANCH && $TF_DESTROY == "true" # Manually destroy integration env.
when: manual
###########################################################################################################
###########################################################################################################
## Dev env.
## * Temporary environment. Lives and dies with the Merge Request.
## * Auto-deploy on push to feature branch.
## * Auto-destroy on when Merge Request is closed.
###########################################################################################################
build_review:
extends: build
rules:
- if: $CI_COMMIT_TAG
when: never
- if: $CI_COMMIT_BRANCH != $CI_DEFAULT_BRANCH
when: on_success
deploy_review:
extends: deploy
dependencies:
- build_review
environment:
name: $environment
action: start
on_stop: destroy_review
# url: https://$CI_ENVIRONMENT_SLUG.example.com
rules:
- if: $CI_COMMIT_TAG
when: never
- if: $CI_COMMIT_BRANCH != $CI_DEFAULT_BRANCH
when: on_success
destroy_review:
extends: destroy
dependencies:
- build_review
environment:
name: $environment
action: stop
rules:
- if: $CI_COMMIT_TAG # Do not destroy production
when: never
- if: $CI_COMMIT_BRANCH == $CI_DEFAULT_BRANCH # Do not destroy staging
when: never
- when: manual
###########################################################################################################
###########################################################################################################
## Second layer
## * Deploys from main branch to qa env.
## * Deploys from tag to production.
###########################################################################################################
.2nd_layer:
stage: 2nd_layer
variables:
TF_ROOT: terraform
trigger:
include: .gitlab-ci/.second-layer.gitlab-ci.yml
# strategy: depend # Do NOT wait for the downstream pipeline to finish to mark upstream pipeline as successful. Otherwise, all pipelines will fail when reaching the pipeline timeout before deployment to 2nd layer.
forward:
yaml_variables: true # Forward variables defined in the trigger job
pipeline_variables: true # Forward manual pipeline variables and scheduled pipeline variables
qa:
extends: .2nd_layer
variables:
TF_STATE_NAME_2: qa
environment: $TF_STATE_NAME_2
TF_CLI_ARGS_plan_2: "-var-file=../vars/$TF_STATE_NAME_2.tfvars"
rules:
- if: $CI_COMMIT_BRANCH == $CI_DEFAULT_BRANCH
production:
extends: .2nd_layer
variables:
TF_STATE_NAME_2: production
environment: $TF_STATE_NAME_2
TF_CLI_ARGS_plan_2: "-var-file=../vars/$TF_STATE_NAME_2.tfvars"
rules:
- if: $CI_COMMIT_TAG
###########################################################################################################
In dieser Phase stellen wir bereits sicher in drei Umgebungen bereit. Das ist meine persönliche Idealempfehlung. Wenn du jedoch mehr Umgebungen benötigst, füge diese deiner CD-Pipeline hinzu.
Du hast sicherlich schon bemerkt, dass wir eine Downstream-Pipeline mit dem Stichwort trigger:include einbinden. Dazu gehört die Datei .gitlab-ci/.second-layer.gitlab-ci.yml. Da wir fast die gleiche Pipeline ausführen wollen, ist ihr Inhalt offensichtlich sehr ähnlich zu dem, den wir oben detailliert beschrieben haben. Der Hauptvorteil bei der Definition dieser Pipeline der zweiten Ebene ist, dass sie allein besteht, was die Definition von Variablen und Regeln erleichtert.
Die Pipeline der zweiten Ebene
Diese Pipeline der zweiten Ebene ist eine brandneue Pipeline. Daher muss es die Definition der ersten Ebene nachahmen mit:
- Aufnahme der Terraform-Vorlage.
- Durchsetzung von Sicherheitskontrollen. Bei der Terraform-Validierung handelt es sich um Duplikate der ersten Ebene. Sicherheitsscanner können jedoch Bedrohungen finden, die noch nicht vorhanden waren, als die Scanner zuvor ausgeführt wurden (z. B. wenn du einige Tage nach der Bereitstellung im Staging in der Produktion bereitstellst).
- Überschreiben von Build- und Bereitstellungs-Jobs, um spezifische Regeln festzulegen. Beachte bitte, dass die Phase
destroynicht mehr automatisiert ist, um zu schnelle Löschvorgänge zu verhindern.
Wie oben erläutert, wurden TF_STATE_NAME und TF_CLI_ARGS_plan von der [Haupt-Pipeline](# the-main-pipeline) zur untergeordneten Pipeline bereitgestellt. Wir brauchten einen weiteren Variablennamen, um diese Werte von der untergeordneten Pipeline hierher, also an die Pipeline der zweiten Ebene, zu übergeben. Deshalb werden sie in der untergeordneten Pipeline mit dem Postfix _2 versehen und der Wert wird während des before_script hier zurück in die entsprechende Variable kopiert.
Da wir oben bereits jeden Schritt aufgeschlüsselt haben, können wir hier direkt auf die breite Ansicht der globalen Definition der zweiten Ebene zoomen (gespeichert in .gitlab-ci/.second-layer.gitlab-ci.yml).
# Use to deploy a second environment on both the default branch and the tags.
include:
template: Terraform.gitlab-ci.yml
stages:
- validate
- test
- build
- deploy
fmt:
rules:
- when: never
validate:
rules:
- when: never
kics-iac-sast:
rules:
- if: $SAST_DISABLED == 'true' || $SAST_DISABLED == '1'
when: never
- if: $SAST_EXCLUDED_ANALYZERS =~ /kics/
when: never
- when: always
###########################################################################################################
## QA env. and Prod. env
## * Manually trigger build and auto-deploy in QA
## * Manually trigger both build and deploy in Production
## * Destroy of these env. is not automated to prevent errors.
###########################################################################################################
build: # terraform plan
cache: # Use a shared cache or tagged runners to ensure terraform can run on apply and destroy
- key: $TF_STATE_NAME_2
fallback_keys:
- cache-$CI_DEFAULT_BRANCH
paths:
- .
environment:
name: $TF_STATE_NAME_2
action: prepare
before_script: # Hack to set new variable values on the second layer, while still using the same variable names. Otherwise, due to variable precedence order, setting new value in the trigger job, does not cascade these new values to the downstream pipeline
- TF_STATE_NAME=$TF_STATE_NAME_2
- TF_CLI_ARGS_plan=$TF_CLI_ARGS_plan_2
rules:
- when: manual
deploy: # terraform apply
cache: # Use a shared cache or tagged runners to ensure terraform can run on apply and destroy
- key: $TF_STATE_NAME_2
fallback_keys:
- cache-$CI_DEFAULT_BRANCH
paths:
- .
environment:
name: $TF_STATE_NAME_2
action: start
before_script: # Hack to set new variable values on the second layer, while still using the same variable names. Otherwise, due to variable precedence order, setting new value in the trigger job, does not cascade these new values to the downstream pipeline
- TF_STATE_NAME=$TF_STATE_NAME_2
- TF_CLI_ARGS_plan=$TF_CLI_ARGS_plan_2
rules:
- if: $CI_COMMIT_BRANCH == $CI_DEFAULT_BRANCH
- if: $CI_COMMIT_TAG && $TF_AUTO_DEPLOY == "true"
- if: $CI_COMMIT_TAG
when: manual
###########################################################################################################
Et voilà. Wir sind bereit. Du kannst die Art und Weise ändern, wie du deine Jobausführungen kontrollierst, indem du bspw. die Möglichkeit von GitLab nutzt, einen Job zu verzögern, bevor du ihn in der Produktion bereitstellst.
Probiere es selbst
Wir haben endlich unser Ziel erreicht. Wir sind jetzt in der Lage, Bereitstellungen in fünf verschiedenen Umgebungen zu kontrollieren, wobei nur die Feature-Branches, der Haupt-Branch und Tags verwendet werden.
- Wir verwenden Open-Source-Vorlagen von GitLab intensiv wieder, um Effizienz und Sicherheit in unseren Pipelines zu gewährleisten.
- Wir nutzen GitLab-Vorlagen, um nur die Blöcke zu überschreiben, die eine benutzerdefinierte Kontrolle benötigen.
- Wir haben die Pipeline in kleine Teile aufgeteilt und kontrollieren die Downstream-Pipelines so, dass sie genau dem entsprechen, was wir brauchen.
Ab hier gehört die Bühne ganz dir. Du kannst beispielsweise die Haupt-Pipeline einfach aktualisieren, um Downstream-Pipelines für deinen Software-Quellcode mit dem Schlüsselwort trigger:rules:changes auszulösen. Und verwende je nach den aufgetretenen Änderungen eine andere Vorlage. Aber das ist eine andere Geschichte.