Updated on: May 14, 2025
4 min read
More granular product usage insights for GitLab Self-Managed and Dedicated
Learn how event-level data helps GitLab improve the DevSecOps platform. Opt-out option is always available.


In GitLab 18.0, we plan to enable event-level product usage data collection from GitLab Self-Managed and GitLab Dedicated instances – while ensuring privacy, transparency, and customer control every step of the way.
We know data powers valuable insights to help you understand the performance of your DevSecOps practices. Similarly, platform usage data enables us to prioritize the investments and product improvements that drive more impact for you.
Historically, we’ve collected both event and aggregate product usage data from GitLab.com. However, for GitLab Self-Managed and Dedicated instances, the absence of event data has required the GitLab Customer Success team to rely on manual data extraction methods to gather key insights, including job runtimes, runner usage for cost optimization, pipeline success rates, and deployment frequency for assessing DevSecOps maturity. Access to event-level data reduces the need for workarounds and enables more efficient reporting and optimizations.
Note: Throughout this blog, when we discuss event collection, we are exclusively referring to the collection of events for all features except those included in GitLab Duo. For more details, please refer to our Customer Product Usage Information page.
Understanding event-level data
Event-level data tracks product usage interactions within the GitLab platform, such as initiating CI/CD pipelines, merging a merge request, triggering a webhook, or creating a new issue. User identifiers are pseudonymized to protect privacy, and GitLab does not undertake any processes to re-identify or associate the metrics with individual users. Importantly, event-level data does not include source code or other customer-created content stored within GitLab. To learn more, visit our Customer Product Usage Information page and event data documentation.
Here is an example of a data sample we collect:

How event-level data collection benefits you
Event-level data offers a wealth of insights beyond what aggregated data can provide. It enables slicing and aggregating pseudonymized system instrumentation to identify trends, highlight unused or underused areas, and signal product improvements. By analyzing usage patterns in context, we can understand which features are used, how, and in what sequence. This visibility uncovers bottlenecks and optimization opportunities that aggregated data would miss.
- In-depth feature usage analysis
Rather than just knowing which features are used weekly or monthly, event-level data provides a clearer picture of how users experience GitLab and the frequency of their usage. This enables us to gain a deeper understanding of user behavior and highlights areas for improvement. - Trend discovery
Event-level data helps identify trends in GitLab adoption that can’t be seen with rolling aggregates. With these insights, the GitLab Customer Success team can help customers make more informed decisions on feature adoption and usage, improving overall efficiency. - Smarter product improvements
Event-level data gives GitLab’s Product team a clearer picture of real-world customer needs. By analyzing usage patterns, product improvements can be aligned with customer priorities, leading to continuous enhancements that make GitLab more powerful, efficient, and user-friendly. - Custom insights for your use case
Event-level data will enable GitLab Customer Success to provide tailored insights based on your organization's overall product usage without identifying individual users. This flexibility helps our teams provide recommendations that address your unique needs and challenges.
You stay in control of your data
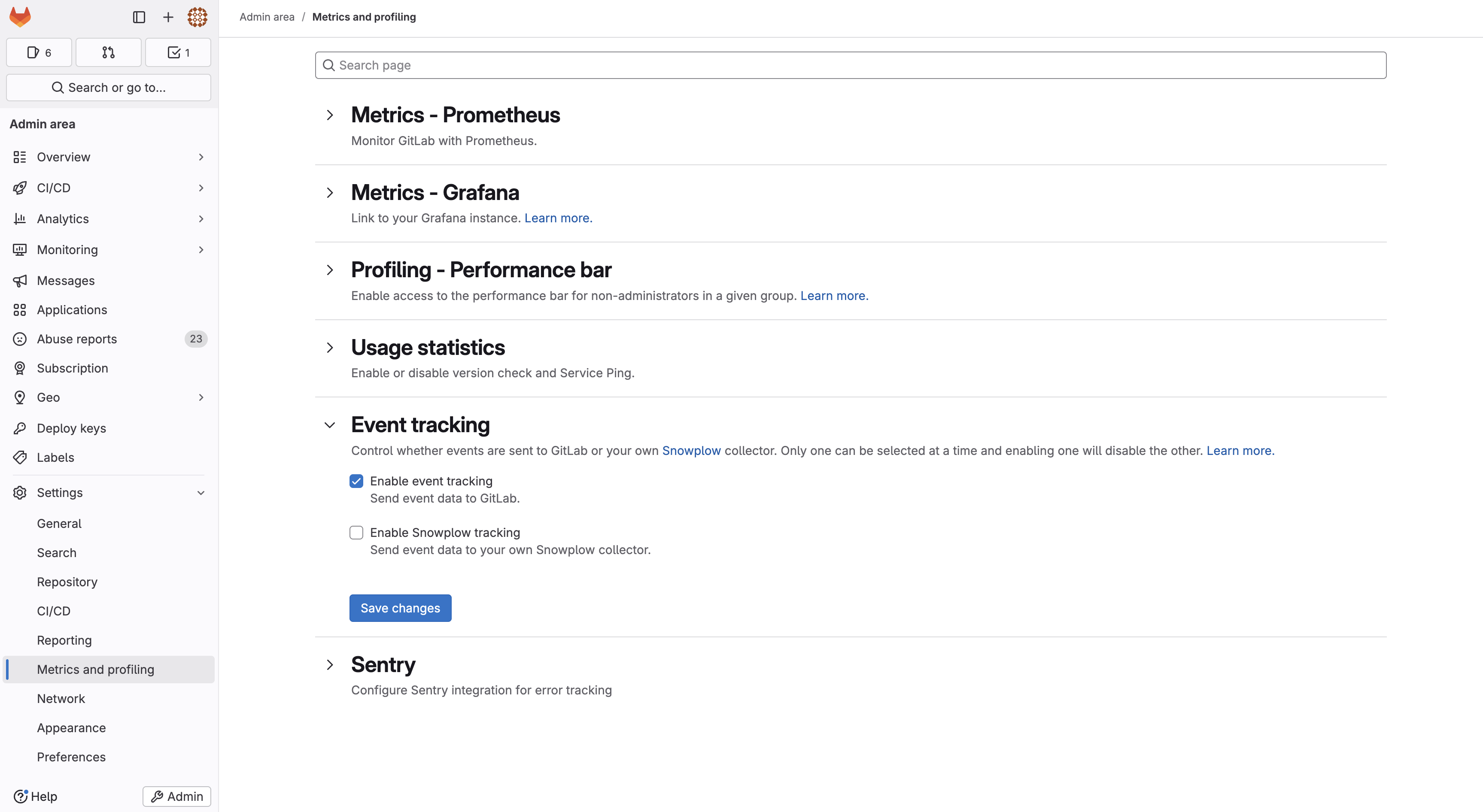
We’re committed to rolling this out with a strong focus on privacy. Here’s what we’re doing to ensure transparency and choice:
✅ Pre-deployment early opt-out – Data sharing can be disabled by instance admins in the 17.11 release before event collection begins in 18.0. The pre-deployment early opt-out option will remain available after 18.0; just upgrade to 17.11 first and disable data sharing.
✅ Proactive communication – Updates on the progress of this initiative shared via blog posts, emails to GitLab admins, and updates through your GitLab account team.
✅ No third-party collectors - GitLab’s event-level instrumentation will not use any third-party collectors; it’s built and operated by GitLab, and events are sent directly to GitLab-managed environments, similar to Service Ping.
✅ Detailed documentation – Detailed documentation is available here, and a list of FAQs is available here.
✅ De-identification approach – We will continue to apply aggregation and/or pseudonymization to any event-level data collected from Self-Managed and Dedicated.
What’s next
- Product enhancements (coming up!) - Improvements to GitLab user experiences and adoption insights made possible by event-level data.
Disclaimer: This blog contains information related to upcoming products, features, and functionality. It is important to note that the information in this blog is for informational purposes only. Please do not rely on this information for purchasing or planning purposes. As with all projects, the items mentioned in this blog and linked pages are subject to change or delay. The development, release, and timing of any products, features, or functionality remain at the sole discretion of GitLab Inc.